
Blog
How Fast Are On-Device LLMs on iPhone 17 Pro and iPad Pro?
Ricky Takkar
Published February 8, 2026
TL;DR: I ran 6 quantized LLMs on Russet which uses Apple's first-party MLX framework on an iPhone 17 Pro and iPad Pro M5, both with 12GB RAM. LFM2.5 1.2B at 4-bit hits \(\text{124 tokens/sec}\) on iPad and \(\text{70 tokens/sec}\) on iPhone. iPad Pro is 1.2x–2.2x faster depending on model and prompt length, with the gap widening dramatically for longer contexts.
Why This Exists
There are plenty of MLX benchmarks for Macs running 20B+ models. There are almost none for iPhones and iPads running the small models that actually fit comfortably in mobile memory. I wanted real numbers for the models I ship in Russet, a private, on-device AI app designed for Apple silicon with no accounts and no ads. So I built a benchmark harness directly into a modified build of the publicly available 2026.02.15 version of the app and ran it systematically on my iPhone and iPad. Also, I needed a break from the cold, and there’s only so much sitting around waiting for M5 Pro/Max chips I can tolerate.
The question I wanted to answer: which sub-1GB quantized model gives the best user experience on the go?
Devices
| Device | Chip | RAM | OS |
| iPhone 17 Pro | A19 Pro | 12 GB | iOS 26.3 RC |
| iPad Pro | M5 | 12 GB | iPadOS 26.3 RC |
Models Tested
| Model | Size | Quantization |
| Qwen3 0.6B | 351 MB | 4-bit |
| LFM2.5 1.2B Instruct | 663 MB | 4-bit |
| Llama 3.2 1B | 713 MB | 4-bit |
| Gemma 3 1B (QAT) | 772 MB | 4-bit |
| LFM2.5 1.2B Instruct | 951 MB | 6-bit |
| Qwen3 1.7B | 984 MB | 4-bit |
These represent the set of MLX models from Hugging Face offered on Russet that can run on both devices without hitting jetsam memory limits (which kill apps consuming roughly 50–67% of total RAM depending on device state).
Methodology
Benchmark Design
Each model was tested with 3 prompts of increasing length to isolate prefill vs. decode performance:
| Prompt | Input Tokens | Output Tokens | What It Tests |
| Short | ~47 | 128 | Decode-dominated (minimal prefill) |
| Medium | ~279 | 256 | Balanced prefill + decode |
| Long | ~690 | 512 | Prefill-heavy, sustained decode |
Critical Methodology Choices
-
Fixed output length (EOS ignored). Most benchmarks let the model stop when it emits an EOS token. This makes TPS numbers incomparable across models — a model that generates 43 tokens looks faster per-token than one generating 512, because it never hits KV cache pressure or thermal throttling. I bypass MLX's internal EOS handling entirely using TokenIterator directly, forcing every model to generate exactly the target token count. A consequential design decision.
-
Deterministic decoding. Temperature = 0 top-p = 1.0 Greedy decoding eliminates sampling variance so TPS numbers reflect pure inference speed, not stochastic branching.
-
Actual tokenizer counts. Input tokens are counted via the MLX tokenizer input.text.tokens.size. Output tokens are counted per-iteration in the generation loop.
-
Fresh KV cache per run. No cache reuse between runs. Each run creates a new RotatingKVCache with a 2048-token limit.
-
Warmup + measured runs. 2 warmup runs (discarded) + 10 measured runs per model per prompt. I report p50 and p90 to capture both typical and tail-case performance.
-
Thermal monitoring. I ran these benchmarks in my upstate New York apartment with the window open in −27.4°F (−33°C) wind chill, holding each device near the window between model runs until it felt cool to the touch. Serious stuff, I know… Anyway, not a single run triggered a .serious thermal state. (ProcessInfo.thermalState was checked between runs.)
-
TTFT vs. decode separation. Time to First Token (TTFT) measures prefill latency. Decode TPS is calculated as \(\frac{(\text{output_tokens} - 1)}{\text{decode_seconds}}\), where decode time excludes the TTFT phase.
What This Measures
This benchmark measures raw SoC inference throughput via the MLX TokenIterator — not the end-to-end generation speed a user experiences. Real-world generation includes per-token text decoding, stop-sequence matching, and UI update overhead, which reduces effective TPS by roughly 10–15%. The numbers here represent the ceiling.
Results
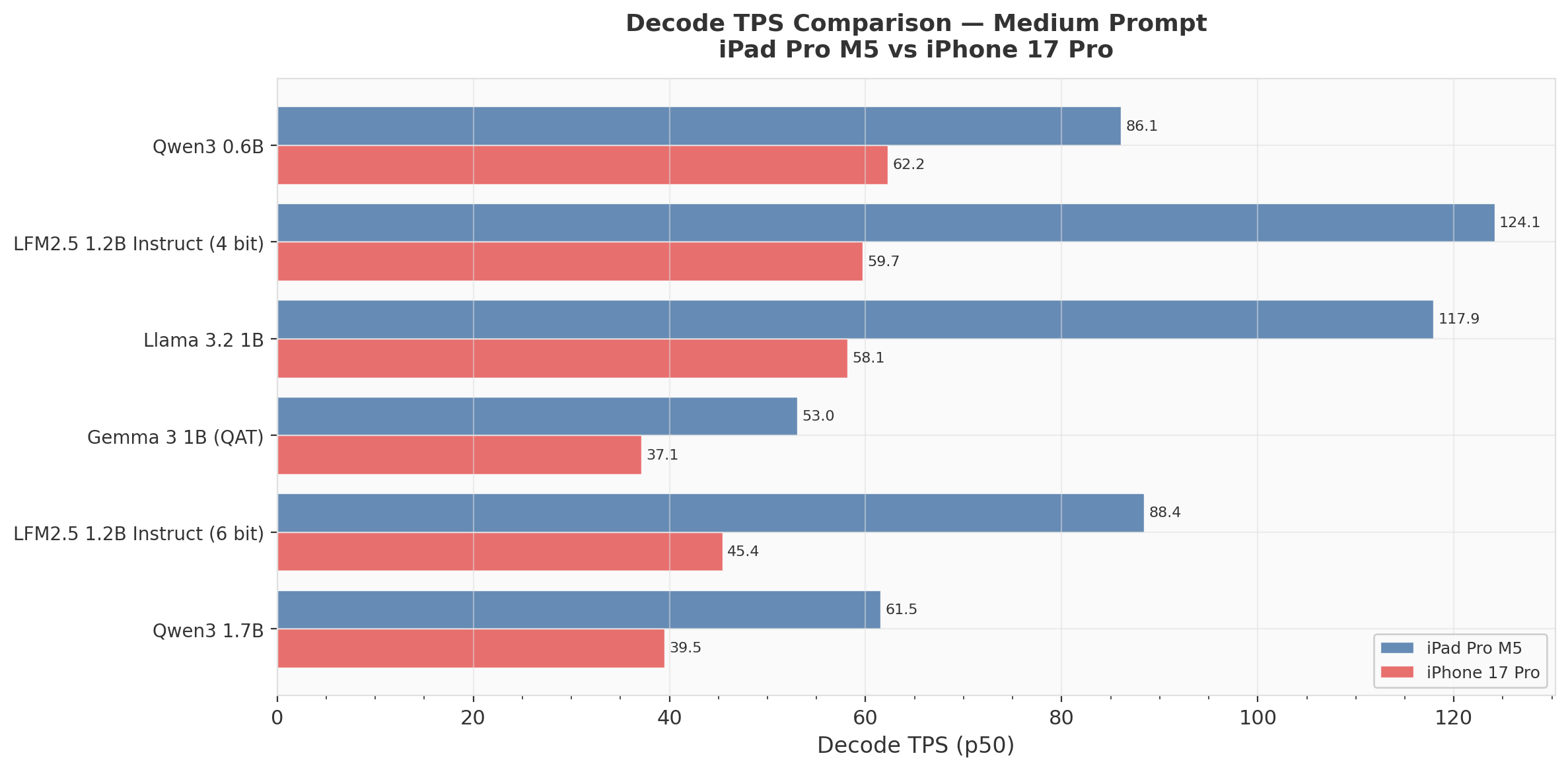
Headline Numbers (Medium Prompt — p50)
| Model | iPhone TPS | iPad TPS | Speedup | iPhone TTFT | iPad TTFT |
| Qwen3 0.6B | 62.2 | 86.1 | 1.38x | 163ms | 100ms |
| LFM2.5 1.2B (4-bit) | 59.7 | 124.1 | 2.08x | 244ms | 125ms |
| Llama 3.2 1B | 58.1 | 117.9 | 2.03x | 253ms | 132ms |
| Gemma 3 1B (QAT) | 37.1 | 53.0 | 1.43x | 693ms | 534ms |
| LFM2.5 1.2B (6-bit) | 45.4 | 88.4 | 1.95x | 280ms | 142ms |
| Qwen3 1.7B | 39.5 | 61.5 | 1.56x | 360ms | 179ms |
LFM2.5 1.2B at 4-bit is the speed champion. \(\text{124 tokens/sec}\) on iPad Pro and \(\text{60 tokens/sec}\) on iPhone — faster than models half its size. LFM's architecture appears extremely well-optimized for the MLX runtime.
iPhone 17 Pro: Decode Speed by Model
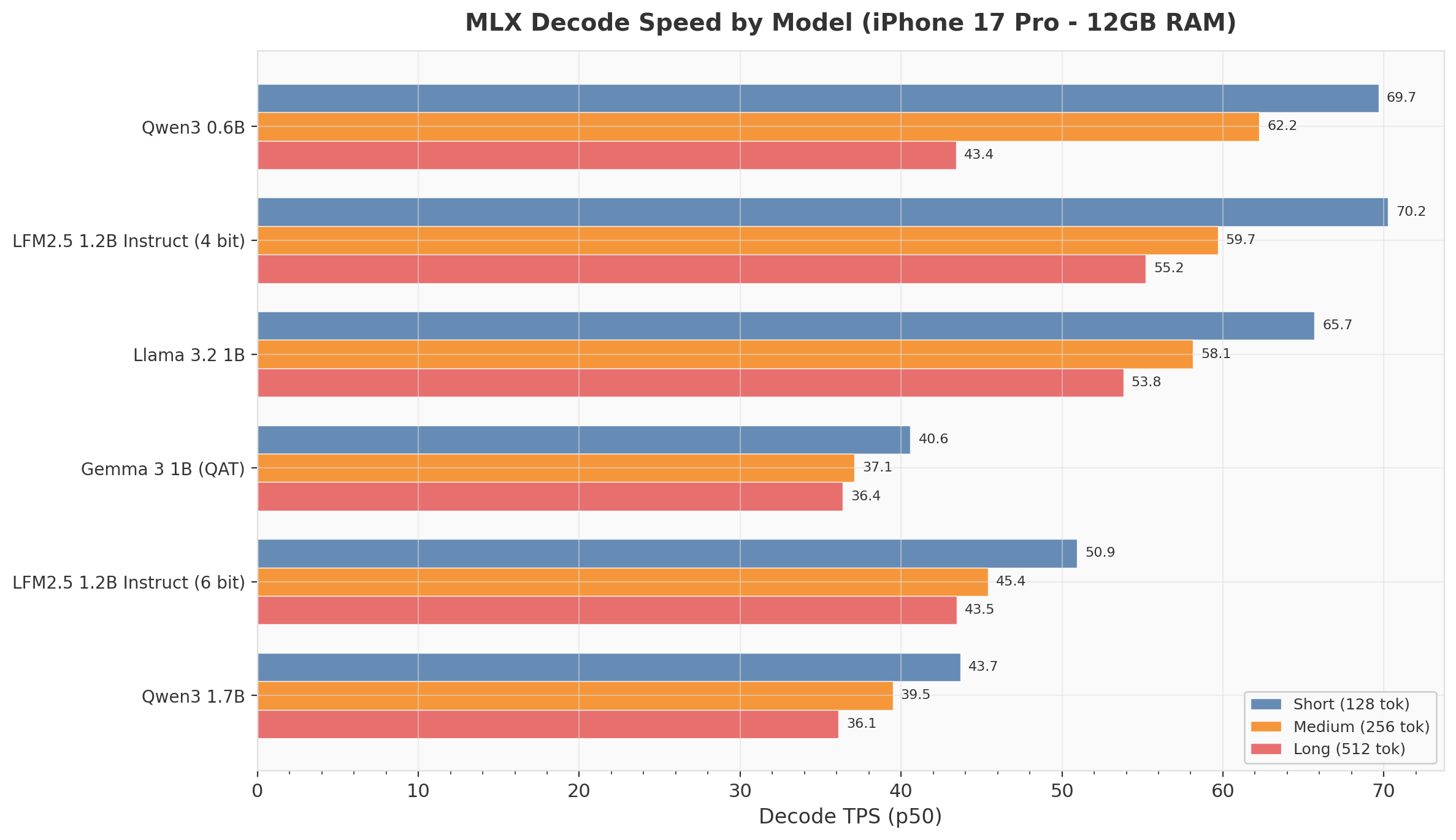
On iPhone, three models cluster at 58–70 TPS for short prompts (Qwen3 0.6B, LFM2.5 4-bit, Llama 3.2 1B), with significant degradation as prompt length increases. Qwen3 0.6B drops from 69.7 to 43.4 TPS (−38%) going from short to long prompts. This is the KV cache pressure effect — as the cache fills, each decode step does more work.
iPad Pro M5: Decode Speed by Model
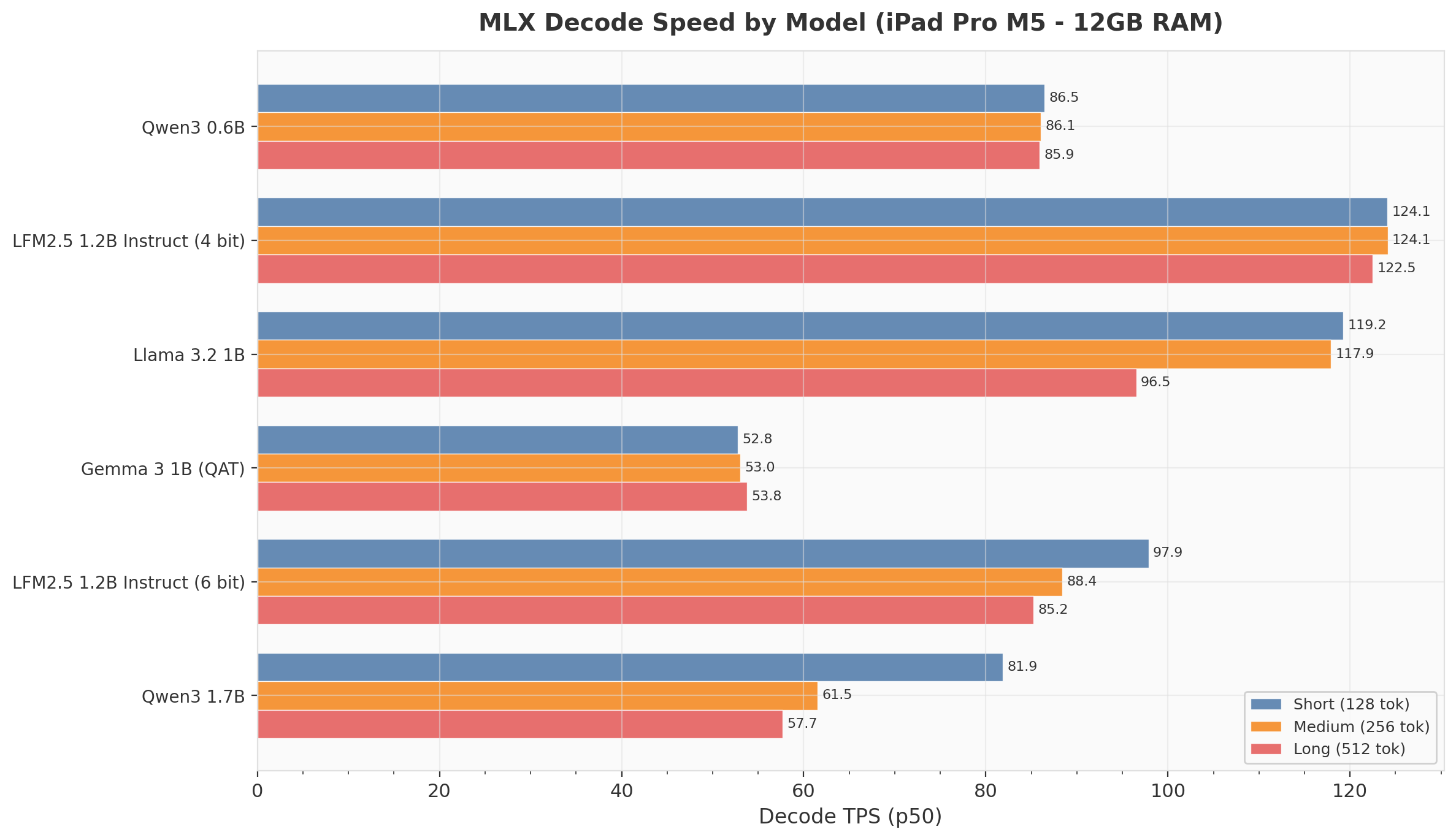
iPad tells a different story. LFM2.5 4-bit shows virtually no degradation: 124.1 / 124.1 / 122.5 TPS across short/medium/long. The M5's memory bandwidth is sufficient that KV cache pressure barely registers for this model. In contrast, Llama 3.2 1B drops from 119 to 97 TPS (−19%), and Qwen3 1.7B drops from 82 to 58 TPS (−29%).
Cross-Device: TPS Comparison
Cross-Device: Speedup Ratio
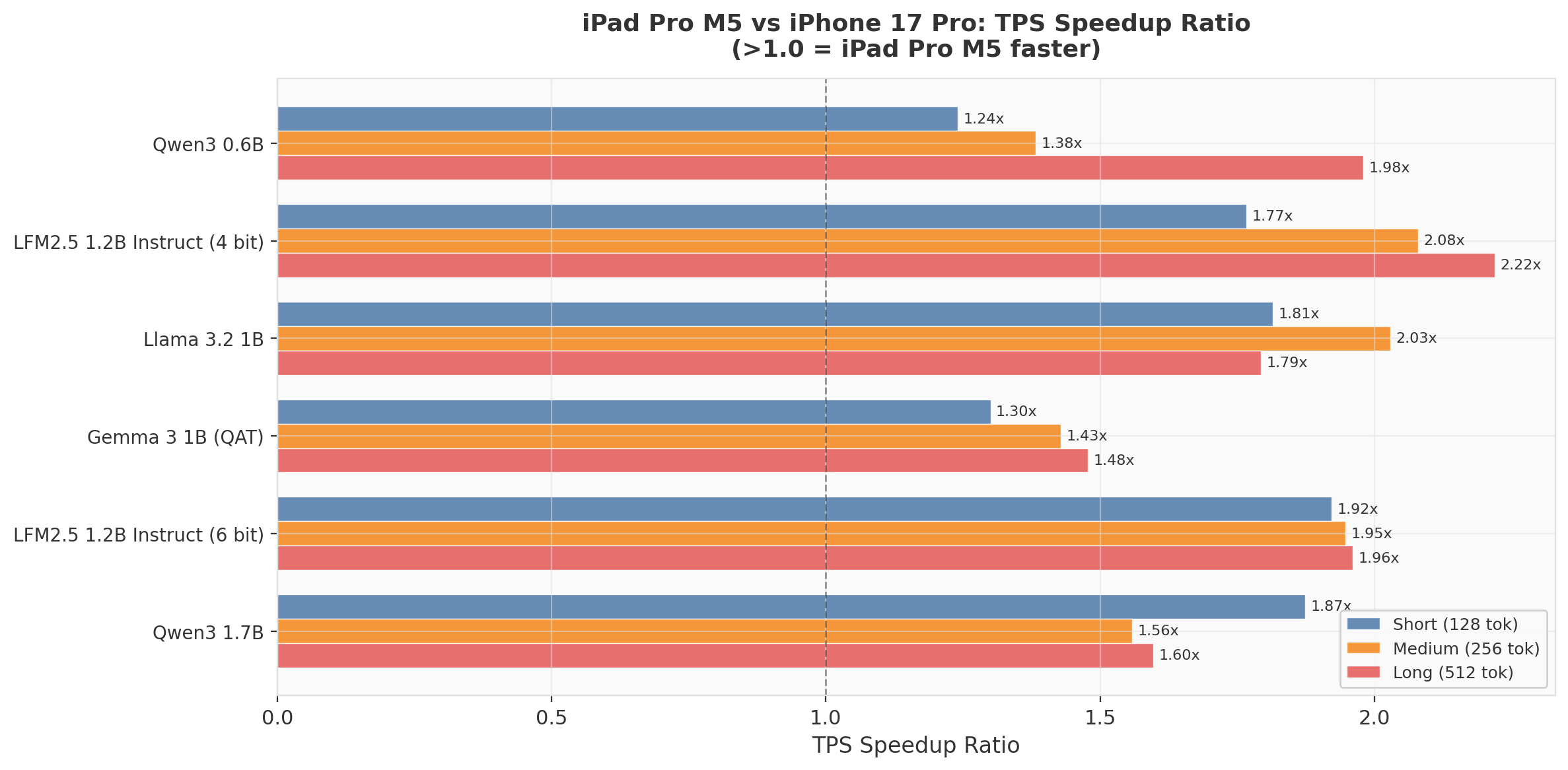
The speedup ratio tells the real story. For short prompts (minimal prefill), iPad is 1.2x–1.9x faster. For long prompts (heavy prefill + sustained decode), the gap widens to 1.5x–2.2x. The advantage compounds with context length because prefill is more memory-bandwidth-sensitive than decode, and the iPad Pro's M5 has substantially higher bandwidth than the iPhone 17 Pro's A19 Pro.
LFM2.5 4-bit shows the largest speedup (2.22x on long prompts), while Gemma 3 1B shows the smallest (1.48x). This suggests LFM's architecture is better at exploiting available bandwidth, while Gemma's bottleneck is elsewhere (likely compute-bound due to its larger attention mechanism).
Cross-Device: Scatter Correlation
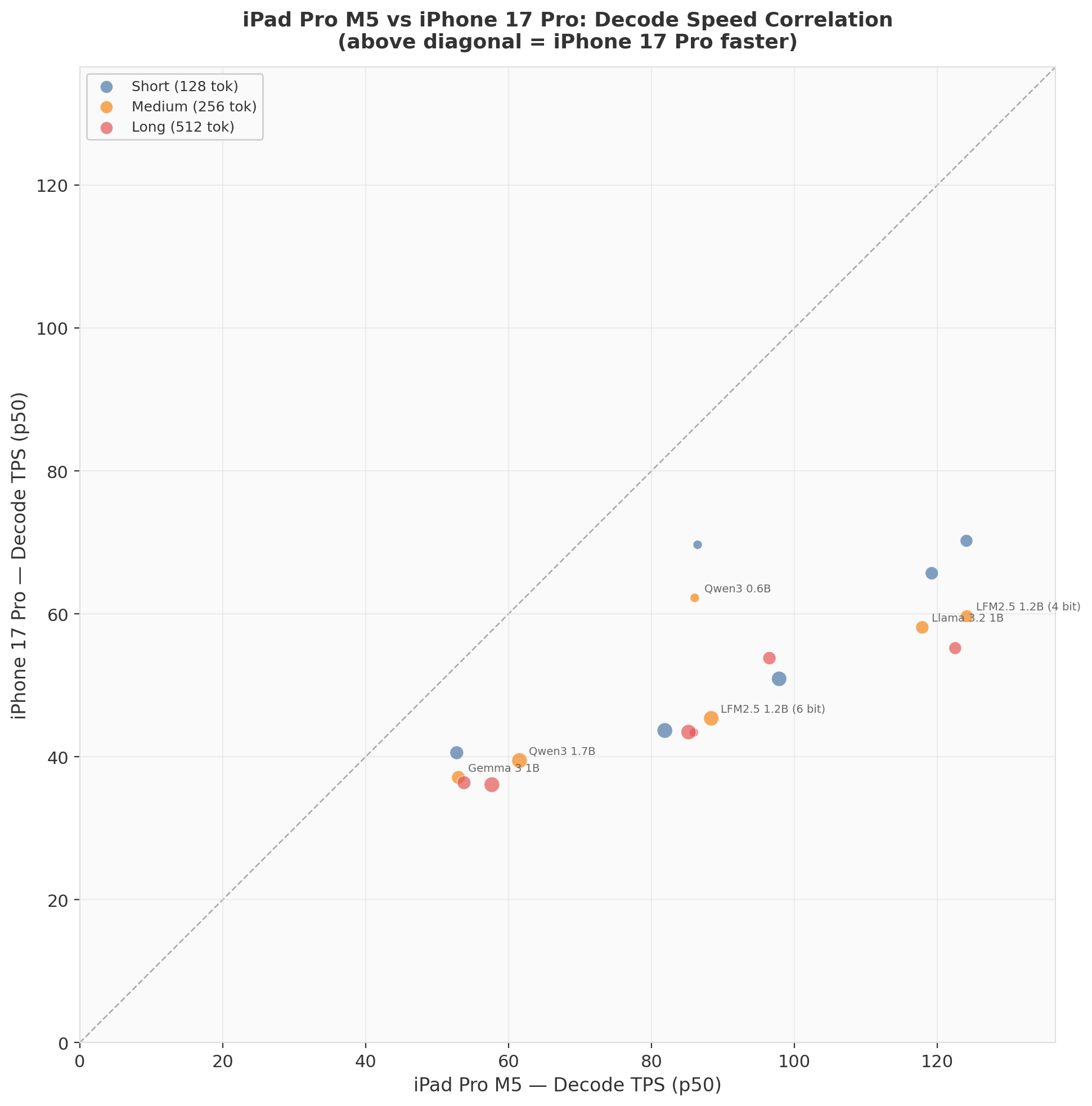
Every point sits below the diagonal (iPad faster). The spread increases from left to right — faster models on iPad see a proportionally larger gap over iPhone. Gemma 3 1B clusters in the lower-left (slow on both devices), while LFM2.5 4-bit occupies the extreme right (fast on iPad, moderate on iPhone). (Spent some extra time making this plot so kept it in.)
Deep Dives
1. Prefill Scaling: Why Gemma 3 1B Is Slow
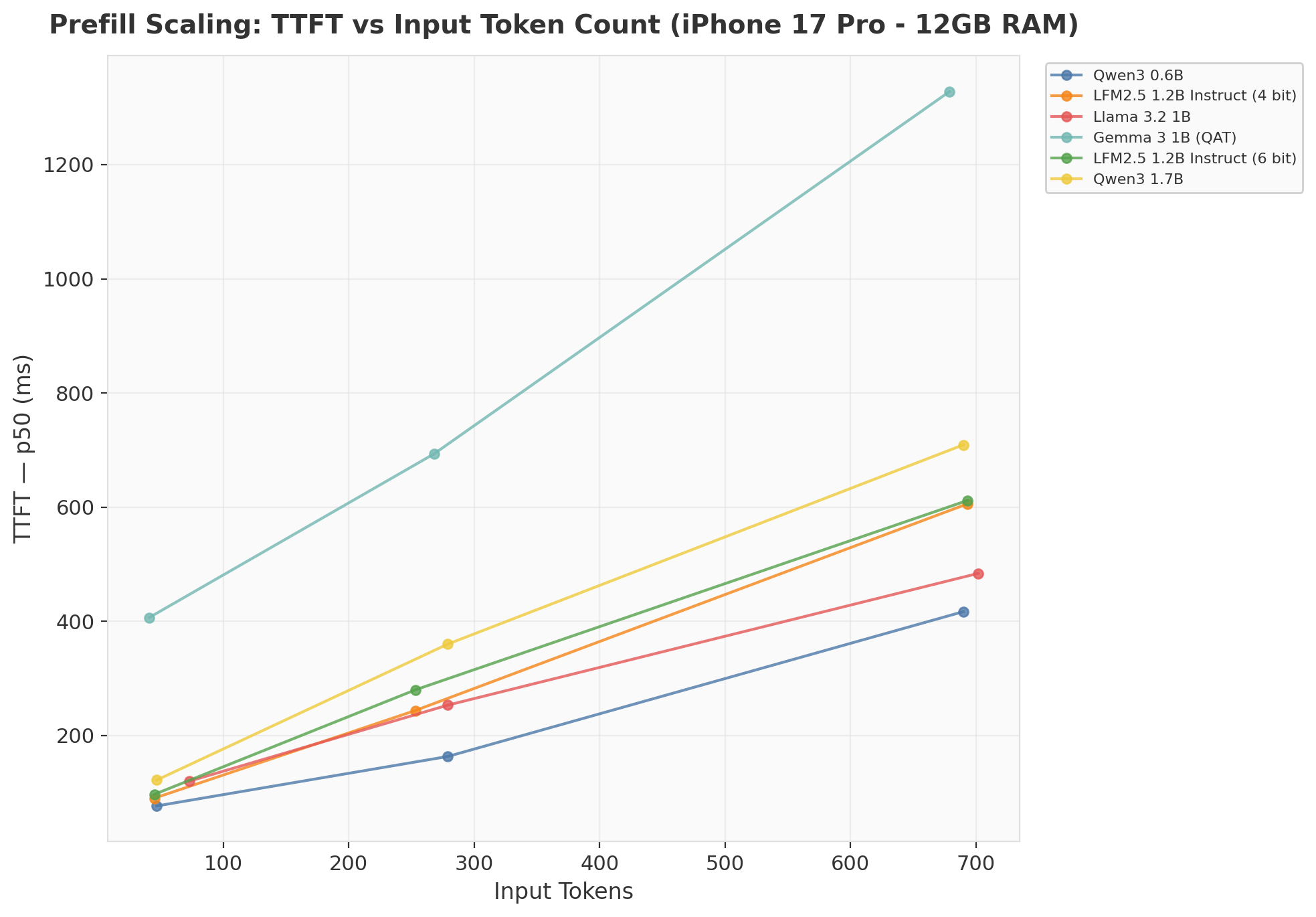
TTFT should scale roughly linearly with input token count (prefill is a single forward pass over all input tokens). Most models follow this pattern. Gemma 3 1B is the exception: its TTFT shoots from 407ms at 47 tokens to 1,330ms at 690 tokens — a 3.3x increase for a 14.7x increase in input tokens.
Why? Gemma 3 uses a different attention pattern (alternating local and global attention layers) and has a larger embedding dimension relative to its parameter count. The QAT (Quantization-Aware Training) variant I tested also uses a non-standard quantization scheme that may not be as optimized in the MLX runtime as the standard GGUF-style quantization used by the other models.
2. LFM2.5: The Quantization Tradeoff
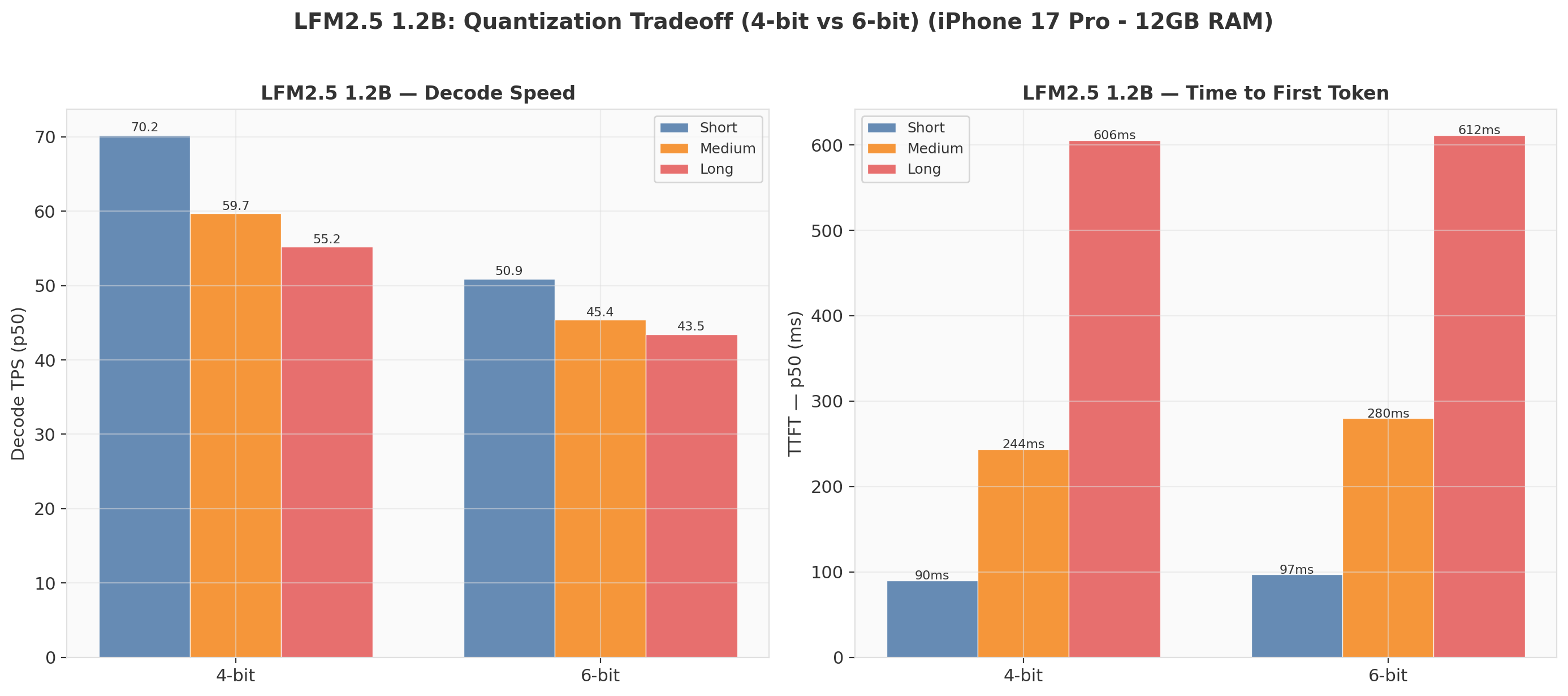
Same architecture, same parameters, different bit widths:
| Metric | 4-bit (663 MB) | 6-bit (951 MB) | Delta |
| Short TPS | 70.2 | 50.9 | −27% |
| Medium TPS | 59.7 | 45.4 | −24% |
| Long TPS | 55.2 | 43.5 | −21% |
| Short TTFT | 90ms | 97ms | +8% |
| Long TTFT | 606ms | 612ms | +1% |
The 4-bit variant is 21–27% faster at decode while using 30% less disk and memory. TTFT is nearly identical because prefill is compute-bound (matrix multiplications scale with model dimension, not bit width for these sizes). The quality tradeoff for 6-bit is hard to justify purely on performance grounds unless your use case demands higher numerical precision. But it doesn't cost me anything to provide it in Russet, so run amok!
3. Thermal Drift on iPhone
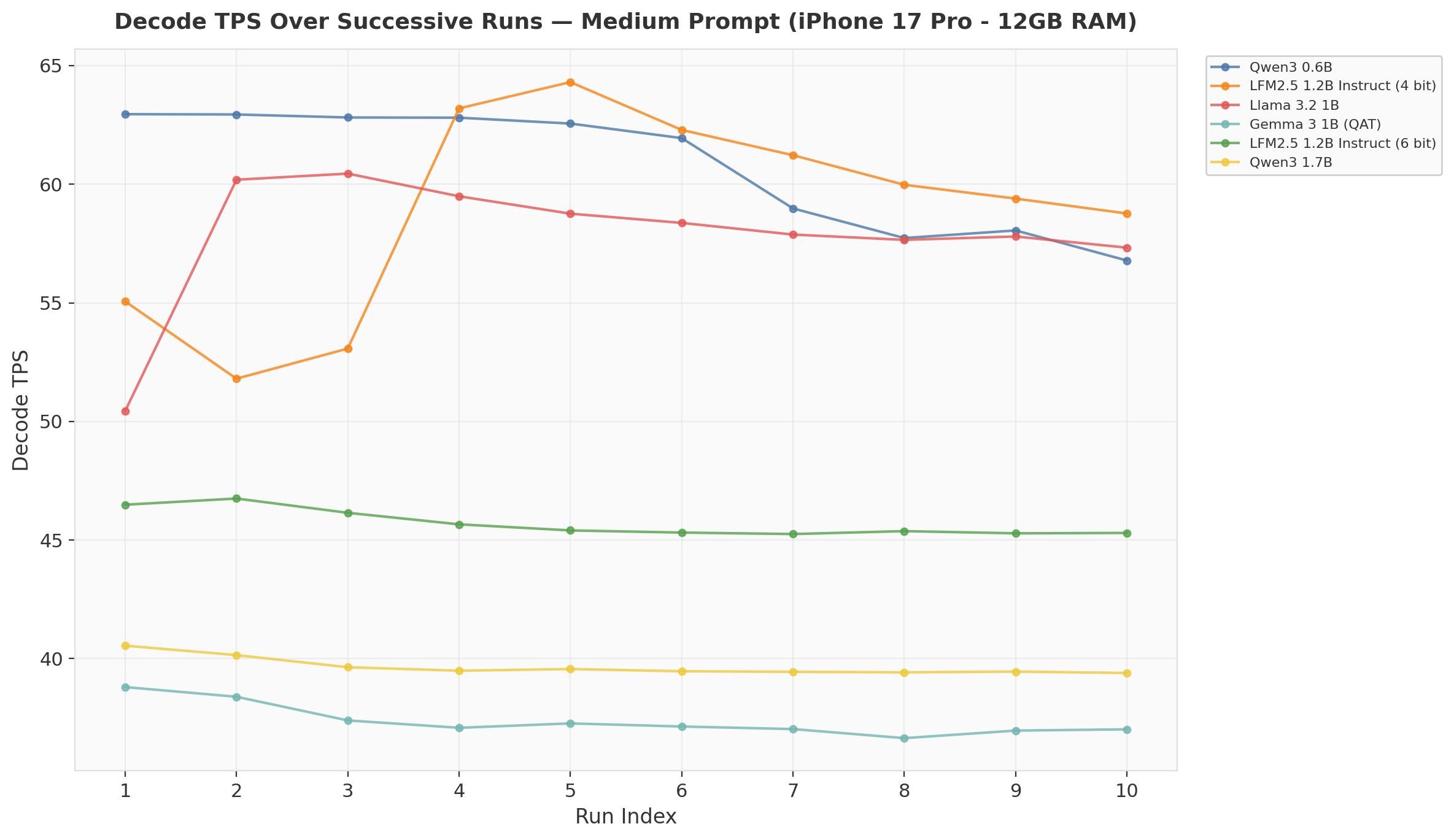
10 successive runs of the medium prompt on iPhone reveal interesting thermal behavior:
-
Qwen3 0.6B starts at 63 TPS and drifts down to 57 TPS by run 10 — a steady 10% decline suggesting gradual thermal throttling.
-
LFM2.5 4-bit does the opposite: starts at 55 TPS, ramps UP to 63 TPS by run 4-5, then slowly declines. This “warm-up” pattern suggests the MLX runtime or GPU scheduler optimizes kernel execution over the first few iterations.
-
Llama 3.2 1B shows the most dramatic ramp: from 50 to 60+ TPS in the first 3 runs.
-
Smaller/slower models (Gemma 3 1B, Qwen3 1.7B) show flat lines — they don't push the hardware hard enough to trigger either optimization or throttling.
The warmup effect is why I discard the first 2 runs and why p50 is more meaningful than mean for these benchmarks.
4. Variance and Reliability
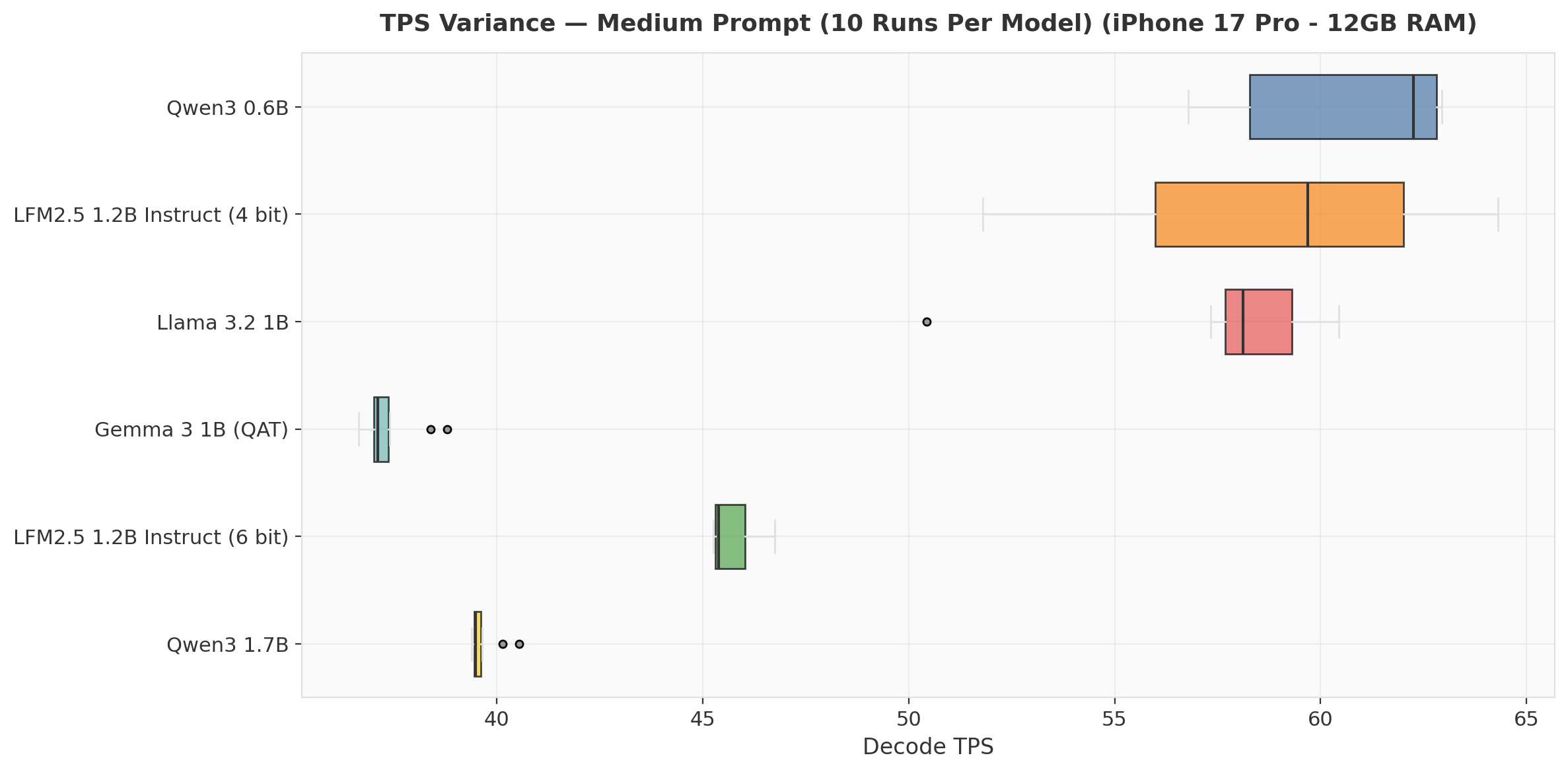
LFM2.5 4-bit has the widest interquartile range (consistent with the ramp-up pattern in the runs chart). Gemma 3 1B and Qwen3 1.7B are the most consistent — tight boxes with minimal spread, likely because they run well below the thermal ceiling.
For latency-sensitive applications, Llama 3.2 1B offers the best consistency-to-speed ratio: tight IQR centered at 58 TPS with no outliers.
Practical Recommendations
Please note that newer, better-optimized models may have been added in Russet since this benchmark was conducted.
-
For iPhone:
-
Best overall: LFM2.5 1.2B 4-bit — 60 TPS, 663 MB, good quality for a 1.2B model
-
Smallest footprint: Qwen3 0.6B — 70 TPS, only 351 MB, best for memory-constrained scenarios
-
Best consistency: Llama 3.2 1B — 58 TPS with tight variance, 713 MB
-
-
For iPad:
-
Speed king: LFM2.5 1.2B 4-bit — 124 TPS, virtually no degradation with context length
-
Best value: Llama 3.2 1B — 118 TPS, proven architecture, wide ecosystem support
-
IMHO skip the 6-bit unless you need it. The 21–27% decode speed penalty for LFM2.5 6-bit vs. 4-bit is substantial, and the TTFT is nearly identical. Unless you've measured a quality difference that matters for your use case, 4-bit is the better default.
Context length matters more on iPhone. iPad Pro maintains near-constant TPS as context grows. iPhone degrades significantly — lucky for you, Russet's UX meticulously plans around this.
Limitations and Caveats
As of this benchmark:
-
Pure inference throughput. Real-world generation includes tokenizer overhead, stop-sequence matching, and UI rendering. Expect 10–15% lower effective TPS in production.
-
EOS ignored. I force generation to a fixed token count. In practice, models stop earlier — a response that would naturally be 50 tokens is measured at 128/256/512 tokens. This is intentional (it makes cross-model comparison fair) but means real-world generation completes faster wall-clock wise.
-
Single-turn only. I don't test multi-turn conversation with accumulated KV cache. Cache reuse across turns would improve TTFT but is a separate benchmark.
-
Quality not measured. TPS tells you nothing about output quality. A faster model that produces worse outputs isn't a better choice. We're benchmarking the engine, not the fuel. (Yes, I admit that analogy came from AI…)
-
iOS memory constraints. Models are limited to what fits within iOS jetsam limits (50ish% of 12 GB total). Larger models (Qwen3 4B, Llama 3.2 3B) couldn't fit and were excluded. Check out Russet for Mac to access the full set of models (warning: model availability also depends on device RAM).
-
Two devices. Both have 12 GB RAM. I can't isolate memory bandwidth from compute throughput differences between A19 Pro and M5. The speedup numbers reflect the combined effect.
Key Takeaways
As of this benchmark:
-
LFM2.5 1.2B 4-bit is the most performant sub-1GB quantized MLX model for mobile. Fastest on both devices, especially dominant on iPad where it hits 124 TPS with no context-length degradation.
-
iPad Pro M5 is 1.2x–2.2x faster than iPhone 17 Pro for on-device LLM inference, despite having the same 12 GB RAM. The gap is memory-bandwidth-driven and widens with context length.
-
Model architecture matters more than parameter count (for mobile). Gemma 3 1B is slower than Qwen3 0.6B despite being larger. LFM2.5 1.2B is faster than everything despite being one of the larger models.
-
4-bit quantization is the sweet spot for mobile. The 6-bit variant of LFM2.5 is 21–27% slower with negligible TTFT difference. Unless you've measured a quality gap, go 4-bit.
-
iPhone TPS degrades significantly with context length; iPad doesn't. On-device AI UX must be designed accordingly — aggressive context management matters more on iPhone.

